【論文読み】Image
Classification at Supercomputer Scale
意義
- レプリカごとのバッチサイズを制御するための分散BacthNormalization
- モデルのスループットを維持しながらの入力パイプラインの最適化
- 勾配の総和を高速で計算するための2DトーラスのAll-Resuce
以上の最適化によってResNet-50に対するImageNetの学習を2.2分で終わらせ76.3%のAccuracyという記録を達成した
↑最適化についてよくわかっていない
背景
浮動小数の計算負荷
ニューラルネットワークではコア上でSGDで最適化するが、収束するまでに非常に多くの浮動小数計算が行われる
- 浮動小数の表示方法から分かるように明らかに計算に時間がかかる
- ResNet-50では
3.2×1016
の浮動小数計算がある
分散深層学習の問題
深層学習の計算時間を短縮するために分散SGDを利用することで複数のデバイス間で並列化することができる。こうした状況では歴史的にしばしば非同期分散SGDが利用される。しかし、非同期分散SGDは収束時間と最終的な検証制度の点から同期SGDと同様にパフォーマンスは得られない(後で読む)。大規模な機械学習においては同期分散学習においてもモデルのクオリティを維持するためには通常と同じような機械学習の技術が必要(ここよくわからん、上のを読む必要あり?)
現状の問題点
- モデルの精度はバッチサイズや各Replicaごとのバッチサイズに依存する
- CPUによる入力がボトルネックになる
- 分散同期SGDでは拡張性の高い(おそらくどのくらいの頻度で行うかということ)All-Redeceが必要
並列分散訓練
うまくまとまっているサイトがあったので参照のこと。
同期分散SGD
深層学習の計算時間を短縮するために多数のプロセス(WorkerまたはReplica)に分散して計算する手法。通常の学習と異なり、BackwardとOptimizeのステップの間にAll-Redeceステップが挟まれる。
イメージは以下の通り。なお、必ずしも各ステップごとにAll-Redeceを行うわけではない。(設計者が定義する必要あり)

All-Reduce
各WorkerがBackwardで求めた勾配の平均を計算し全てのWorkerに配る。その後のOptimizeステップではこうして求められた平均の勾配が利用される。All-Redeceでは全てのプロセスが持っている配列データを集約しその結果を再配分する操作を指す。
(参照)
非同期分散SGD
各Workerが求めた勾配をパラメーターサーバに送信し、その勾配を用いてパラメータサーバが各Workerの平均勾配を計算し重みを更新する。各Workerは次の訓練を開始する前に、パラメーターサーバから最新の鮮度の高い勾配を取得し、それを用いて訓練を行う。
アルゴリズムは以下。

[Jianmin Chen, Rajat Monga,
Samy Bengio, and Rafal Józefowicz, 2016]
方法
混合精度の利用
各ステップごとに異なる精度の浮動小数を利用することで高速化を図る。
-
畳み込み層、入力画像、アクティベーション
16bit(半精度floatまたはhalf)を利用。モデル内の全ての浮動小数計算の中で畳み込み層が占める割合が圧倒的に多く、計算とメモリアクセスのオーバーヘッドの体部分を占めているため。精度を下げてもほとんど(全く)モデルの精度に影響がないらしい。
-
その他(Batch Normalization、loss計算、勾配の合計など)
32bitを利用。精度の維持が目的。
学習率
学習率はバッチサイズに比例させると良いという研究結果をもとに(後で読む)linear
learning rate scalingを採用(バッチサイズを2倍すると同時に学習率も2倍にする)。さらに段階的な学習速度のウォームアップと学習速度の減衰を利用(何それ)。
バッチサイズ
LARS最適化によってモデルのクオリティを下げることなくバッチサイズを32768まで向上させることができる。これによってTPUにおけるスループットも上昇させることができる。
スループット
モデルにデータを食わせる速度
Distributed Batch
Normalization
以前までの問題点
-
通常の分散深層学習においてはBatch Normalizationは各Workerごとに行うことで通信によるオーバヘッドを削減する。
-
実際にはバッチサイズによってモデルの性能が大きく変動する
- ResNet-50では各replicaのバッチサイズを32以下にすると検証精度のピークで収束しなくなる
- Batch Normalizationにおいては学習時と推論時で正規化のされ方が異なる(方法は様々あるが、一般的には学習時の全体の平均と分散を覚えておく)ことが原因。
- バッチサイズが小さい
母集団の統計量から乖離してしまう
- 事例が独立同分布でない
バッチごとに過学習してしまう
-
大規模にデータを並列して学習させるには、全体のバッチサイズ大きくするまたはreplicaごとのバッチサイズを小さくさせる必要がある。(常識的に考えてあたり前)一方で全体のバッチサイズが大きくなるほど学習に悪影響をもたらすことが示されている。
- 同じエポック数で学習を行う場合、イテレーション数が減ってしまうため、モデルが成熟しない。
- 勾配の分散が小さくなること(多分各バッチの目的関数がほとんど同じ形になってしまうこと)により、性質の悪い局所解(sharp minima
と呼ばれます)に進みやすくなってしまい、結果として得られるモデルの汎化性能が悪くなってしまう。
提案手法
- レプリカごとに平均と分散を計算
- いくつかのレプリカをサブグループとしてまとめ、1.を利用してサブグループの平均と分散を計算
- 以上をBatch Normalizationの平均と分散として利用する

このようにすることでサブグループの数によってBatch Normalizationに利用するバッチ数を全体のバッチ数から独立して制御することができる
分析
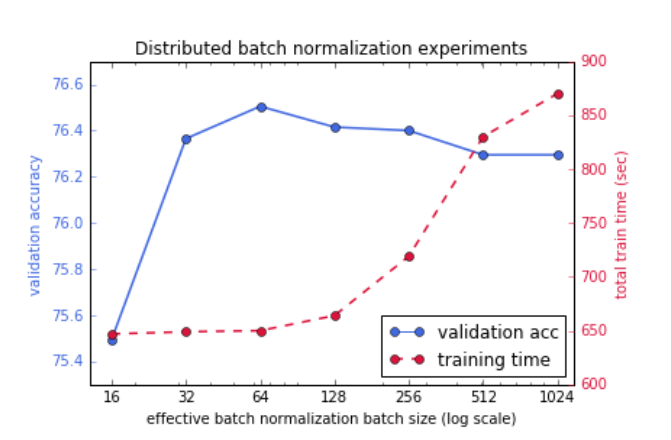
以下にグループサイズの大きさと検証精度及びトレーニング時間との関係を示す。この実験はアクセラレータとしてTPU v2
Podを利用しており、LARS最適化をせずにResNet-50をImageNetで学習させている。効果を及ぼすバッチサイズが16の時、すなわちグループサイズが1の時(=レプリカがそれぞれ平均と分散を共有しない時)をベースラインとするとバッチサイズが64、すなわちグループサイズを4としたときに最も検証精度が高い。
以前までの問題点
- ファイルの入力、パース、前処理、シャッフル等のインプットがfoward backward処理よりも遅くなった場合、ボトルネックとなる
- 実際多くの面でこうした処理はアクセラレータ上でサポートされていないため、CPUで処理するしかない
提案手法
データセットの共有とキャッシュ
本来ならば一度読み込んだデータセットはそれ以上利用しなくなるまでホストのメモリ上に保持していたいが、実際にはデータセットは膨大であるため不可能。大量のワーカーを利用することによって、ワーカー間でのデータセットの共有及び効率的なアクセスパターンの実現が可能となる。
入力や計算に向けたデータの事前読み込み
CPUアクセラレータ上でバッチ学習をしている間、次のバッチを入力パイプラインで同時に処理することで、CPUとアクセラレータ間での待機時間の短縮を行うことができる。
さらに、ImageNet データセットにはさまざまなサイズのイメージがあるため、小さなイメージを処理するときにプリフェッチによってヘッドルームが作成されるため、より大きなイメージを処理する必要がある場合でも、デバイスの前にとどまることができます。(よくわからん)
JPEGのデコードとトリミング
ImageNetなどのデータセットは多くの場合、JPEGにエンコードされている。トリミングはData
Augmentationとして利用される。元の画像をデコードしてからパースするよりもトリミングした後にエンコードされた画像の関連部分だけを取り出す方がオーバーヘッドが少なく効率的
データパースの並列
データのパースや前処理は入力パイプラインの中でも最も負荷の高いものとなることがある。マルチコアのCPUによって並列化することによってスループットを向上させることができる。
分析
以下に提案した4つの手法を加えた場合、及び削除した場合のスループットの変化を示す。なお、全ての実験は1台のIntel
Skylakeプロセッサーを用いて、TensorFlowのAPIを利用している。この実験の結果は2000万枚の画像を1000枚ごとに平均して実行されたものであり、値はホストCPUごとに観測された平均のスループットである。
この実験結果から並列化が最も効果的であり、ベースラインの2倍以上のスループットを記録している。

2次元の勾配和計算
以前までの問題点
以前のAll-Redeceではリングベースで全体の勾配和計算が行われていたが、TPU Podにおいては、チャンクを全てのプロセスに渡って運ぶ遅延によって制限されていた。
リングベースのAll-Redece
総プロセス数
P
とし、各プロセスに
1
から
P
までの番号がついているとする。そしてあるプロセス
p
はプロセス
p+1
と接続していると考える。ただし、プロセス
P
はプロセス
1
に接続しており、全体としてリングを構成しているものとする。この時、次のアルゴリズムによってAll-Redeceを計算する
- プロセス
p
は自身の配列を
P
個のチャンクに分割する。この時、
p
個目のチャンクを
[p]
と表す。
-
[p]
をプロセス
p+1
へと送信し、同時にプロセス
p−1
から受信した
[p−1]
を自身の
[p−1]
と足し合わせる(=集約する)。
- 足し合わせた
[p−1]
を再びプロセス
p+1
に送信する。
- 1-3の操作を
P−1
回繰り返す。
- 各プロセスはは集約済みのチャンクを一つずつ保持することになるため、各々がリング上にあるチャンクに自分のチャンクを併せていくことで最終的に全プロセスのチャンクの集約を手に入れることができる。
提案手法
総プロセス数を
P2
とし、各プロセスを2次元に並べた場合を考える。それぞれが持つテンソル(上で言う配列)を半分に分割する。そして以下の2段階の処理を行う。
第一段階
- 左半分のテンソルは各々縦方向に、右半分のテンソルは横方向にそれぞれリングを構成する。
- 構成されたリングに対してリングベースのAll-Redece処理を適応する
第二段階
- 左半分のテンソルは横方向、右半分のテンソルは縦方向にリングを構成する
- 第一段階と同様にAll-Redeceを適応する

3×3
のプロセスの場合の処理
分析
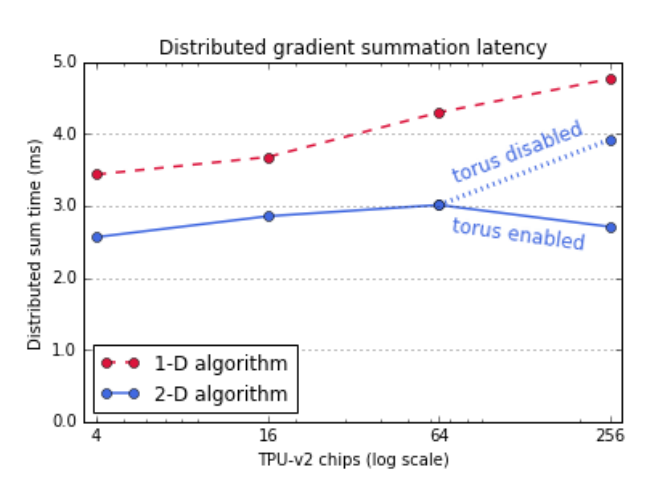
以下にResNet-50の学習がTPU
v2チップの数によってどのように変化するかを示したグラフを示す。2次元の勾配計算和計算は1次元と比べて遅延が少なく、高いスループットを維持する。256チップではトーラスのリンクはより効率的に計算が行われていることが読み取れる。
結果
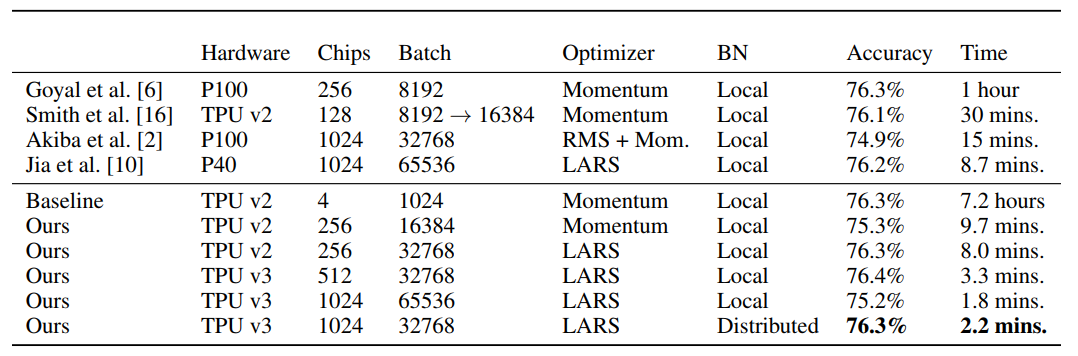
以下にResNet-50をImageNetで学習した結果を示す。比較対象は公表当時SOTAであったものである。なお、必要なエポック数を減らすことでより精度を改善できることが期待されるが、他の他の手法と比較できるように、意図的にエポック数を90としている。なお、時間の計測はTPUバイナリのジャストインタイムコンパイルが終了した瞬間からファイルに終了時間を書き込むまでとしている。精度は検証セットからブラックリストサンプルを抜いたものに対して計測したものである。
以下メモ
大きなバッチ学習
大きなバッチサイズを設けた学習では汎化性能が落ちてしまうという問題がある。これは、各バッチの目的関数がほとんど同じ形をしてしまうことで局所解に陥りやすくなるため(と聞いたことがある・・・)
参考
エポック数の話
chainerMNの話
【論文読み】Image Classification at Supercomputer Scale
意義
以上の最適化によってResNet-50に対するImageNetの学習を2.2分で終わらせ76.3%のAccuracyという記録を達成した
↑最適化についてよくわかっていない
背景
浮動小数の計算負荷
ニューラルネットワークではコア上でSGDで最適化するが、収束するまでに非常に多くの浮動小数計算が行われる
分散深層学習の問題
深層学習の計算時間を短縮するために分散SGDを利用することで複数のデバイス間で並列化することができる。こうした状況では歴史的にしばしば非同期分散SGDが利用される。しかし、非同期分散SGDは収束時間と最終的な検証制度の点から同期SGDと同様にパフォーマンスは得られない(後で読む)。大規模な機械学習においては同期分散学習においてもモデルのクオリティを維持するためには通常と同じような機械学習の技術が必要(ここよくわからん、上のを読む必要あり?)
現状の問題点
並列分散訓練
うまくまとまっているサイトがあったので参照のこと。
同期分散SGD
深層学習の計算時間を短縮するために多数のプロセス(WorkerまたはReplica)に分散して計算する手法。通常の学習と異なり、BackwardとOptimizeのステップの間にAll-Redeceステップが挟まれる。

イメージは以下の通り。なお、必ずしも各ステップごとにAll-Redeceを行うわけではない。(設計者が定義する必要あり)
All-Reduce
各WorkerがBackwardで求めた勾配の平均を計算し全てのWorkerに配る。その後のOptimizeステップではこうして求められた平均の勾配が利用される。All-Redeceでは全てのプロセスが持っている配列データを集約しその結果を再配分する操作を指す。
(参照)
非同期分散SGD
各Workerが求めた勾配をパラメーターサーバに送信し、その勾配を用いてパラメータサーバが各Workerの平均勾配を計算し重みを更新する。各Workerは次の訓練を開始する前に、パラメーターサーバから最新の鮮度の高い勾配を取得し、それを用いて訓練を行う。
アルゴリズムは以下。
[Jianmin Chen, Rajat Monga, Samy Bengio, and Rafal Józefowicz, 2016]
方法
混合精度の利用
各ステップごとに異なる精度の浮動小数を利用することで高速化を図る。
畳み込み層、入力画像、アクティベーション
16bit(半精度floatまたはhalf)を利用。モデル内の全ての浮動小数計算の中で畳み込み層が占める割合が圧倒的に多く、計算とメモリアクセスのオーバーヘッドの体部分を占めているため。精度を下げてもほとんど(全く)モデルの精度に影響がないらしい。
その他(Batch Normalization、loss計算、勾配の合計など)
32bitを利用。精度の維持が目的。
学習率
学習率はバッチサイズに比例させると良いという研究結果をもとに(後で読む)linear learning rate scalingを採用(バッチサイズを2倍すると同時に学習率も2倍にする)。さらに段階的な学習速度のウォームアップと学習速度の減衰を利用(何それ)。
バッチサイズ
LARS最適化によってモデルのクオリティを下げることなくバッチサイズを32768まで向上させることができる。これによってTPUにおけるスループットも上昇させることができる。
スループット
モデルにデータを食わせる速度
Distributed Batch Normalization
以前までの問題点
通常の分散深層学習においてはBatch Normalizationは各Workerごとに行うことで通信によるオーバヘッドを削減する。
実際にはバッチサイズによってモデルの性能が大きく変動する
母集団の統計量から乖離してしまう
バッチごとに過学習してしまう
大規模にデータを並列して学習させるには、全体のバッチサイズ大きくするまたはreplicaごとのバッチサイズを小さくさせる必要がある。(常識的に考えてあたり前)一方で全体のバッチサイズが大きくなるほど学習に悪影響をもたらすことが示されている。
提案手法
このようにすることでサブグループの数によってBatch Normalizationに利用するバッチ数を全体のバッチ数から独立して制御することができる
分析
以下にグループサイズの大きさと検証精度及びトレーニング時間との関係を示す。この実験はアクセラレータとしてTPU v2 Podを利用しており、LARS最適化をせずにResNet-50をImageNetで学習させている。効果を及ぼすバッチサイズが16の時、すなわちグループサイズが1の時(=レプリカがそれぞれ平均と分散を共有しない時)をベースラインとするとバッチサイズが64、すなわちグループサイズを4としたときに最も検証精度が高い。
Input pipeline optimization
以前までの問題点
提案手法
データセットの共有とキャッシュ
本来ならば一度読み込んだデータセットはそれ以上利用しなくなるまでホストのメモリ上に保持していたいが、実際にはデータセットは膨大であるため不可能。大量のワーカーを利用することによって、ワーカー間でのデータセットの共有及び効率的なアクセスパターンの実現が可能となる。
入力や計算に向けたデータの事前読み込み
CPUアクセラレータ上でバッチ学習をしている間、次のバッチを入力パイプラインで同時に処理することで、CPUとアクセラレータ間での待機時間の短縮を行うことができる。
さらに、ImageNet データセットにはさまざまなサイズのイメージがあるため、小さなイメージを処理するときにプリフェッチによってヘッドルームが作成されるため、より大きなイメージを処理する必要がある場合でも、デバイスの前にとどまることができます。(よくわからん)JPEGのデコードとトリミング
ImageNetなどのデータセットは多くの場合、JPEGにエンコードされている。トリミングはData Augmentationとして利用される。元の画像をデコードしてからパースするよりもトリミングした後にエンコードされた画像の関連部分だけを取り出す方がオーバーヘッドが少なく効率的
データパースの並列
データのパースや前処理は入力パイプラインの中でも最も負荷の高いものとなることがある。マルチコアのCPUによって並列化することによってスループットを向上させることができる。
分析
以下に提案した4つの手法を加えた場合、及び削除した場合のスループットの変化を示す。なお、全ての実験は1台のIntel Skylakeプロセッサーを用いて、TensorFlowのAPIを利用している。この実験の結果は2000万枚の画像を1000枚ごとに平均して実行されたものであり、値はホストCPUごとに観測された平均のスループットである。
この実験結果から並列化が最も効果的であり、ベースラインの2倍以上のスループットを記録している。
2次元の勾配和計算
以前までの問題点
以前のAll-Redeceではリングベースで全体の勾配和計算が行われていたが、TPU Podにおいては、チャンクを全てのプロセスに渡って運ぶ遅延によって制限されていた。
リングベースのAll-Redece[1]
総プロセス数P
とし、各プロセスに
1
から
P
までの番号がついているとする。そしてあるプロセス
p
はプロセス
p+1
と接続していると考える。ただし、プロセス
P
はプロセス
1
に接続しており、全体としてリングを構成しているものとする。この時、次のアルゴリズムによってAll-Redeceを計算する
提案手法
総プロセス数をP2
とし、各プロセスを2次元に並べた場合を考える。それぞれが持つテンソル(上で言う配列)を半分に分割する。そして以下の2段階の処理を行う。
第一段階
第二段階
分析
以下にResNet-50の学習がTPU v2チップの数によってどのように変化するかを示したグラフを示す。2次元の勾配計算和計算は1次元と比べて遅延が少なく、高いスループットを維持する。256チップではトーラスのリンクはより効率的に計算が行われていることが読み取れる。
結果
以下にResNet-50をImageNetで学習した結果を示す。比較対象は公表当時SOTAであったものである。なお、必要なエポック数を減らすことでより精度を改善できることが期待されるが、他の他の手法と比較できるように、意図的にエポック数を90としている。なお、時間の計測はTPUバイナリのジャストインタイムコンパイルが終了した瞬間からファイルに終了時間を書き込むまでとしている。精度は検証セットからブラックリストサンプルを抜いたものに対して計測したものである。
以下メモ
大きなバッチ学習
大きなバッチサイズを設けた学習では汎化性能が落ちてしまうという問題がある。これは、各バッチの目的関数がほとんど同じ形をしてしまうことで局所解に陥りやすくなるため(と聞いたことがある・・・)
参考
[2][1:1]
エポック数の話
chainerMNの話
https://jinbeizame.hateblo.jp/entry/understanding_batchnorm ↩︎ ↩︎
https://www.slideshare.net/DeepLearningJP2016/dlbatch-renormalization-towards-reducing-minibatch-dependence-in-batchnormalized-models ↩︎